聚类
Sentence-Transformers 可以通过不同方式对或大或小的句子集进行聚类。
K-均值 (k-Means)
kmeans.py 包含一个使用 K-均值聚类算法 的示例。K-均值要求事先指定聚类的数量。句子会被聚类成大小大致相等的组。
层次聚类 (Agglomerative Clustering)
agglomerative.py 展示了一个使用 层次聚类 和 层次聚类算法 的示例。与 K-均值不同,我们可以为聚类指定一个阈值:低于该阈值的簇将被合并。如果簇的数量未知,这个算法可能很有用。通过阈值,我们可以控制是想要许多小的、细粒度的簇,还是少数粗粒度的簇。
快速聚类
对于较大的数据集,层次聚类相当慢,因此它可能只适用于几千个句子。
在 fast_clustering.py 中,我们提出了一种针对大型数据集(不到 5 秒可处理 5 万个句子)优化的聚类算法。它在一个庞大的句子列表中搜索局部社区:一个局部社区是一组高度相似的句子。
您可以配置余弦相似度的阈值,用于判断两个句子是否相似。此外,您还可以指定局部社区的最小规模。这使您既可以获得大的粗粒度簇,也可以获得小的细粒度簇。
我们将其应用于 Quora 重复问题 数据集,输出结果如下所示:
Cluster 1, #83 Elements
What should I do to improve my English ?
What should I do to improve my spoken English?
Can I improve my English?
...
Cluster 2, #79 Elements
How can I earn money online?
How do I earn money online?
Can I earn money online?
...
...
Cluster 47, #25 Elements
What are some mind-blowing Mobile gadgets that exist that most people don't know about?
What are some mind-blowing gadgets and technologies that exist that most people don't know about?
What are some mind-blowing mobile technology tools that exist that most people don't know about?
...
主题建模
主题建模是在文档集合中发现主题的过程。
下图展示了一个示例,显示了在 20 个新闻组数据集中识别出的主题:
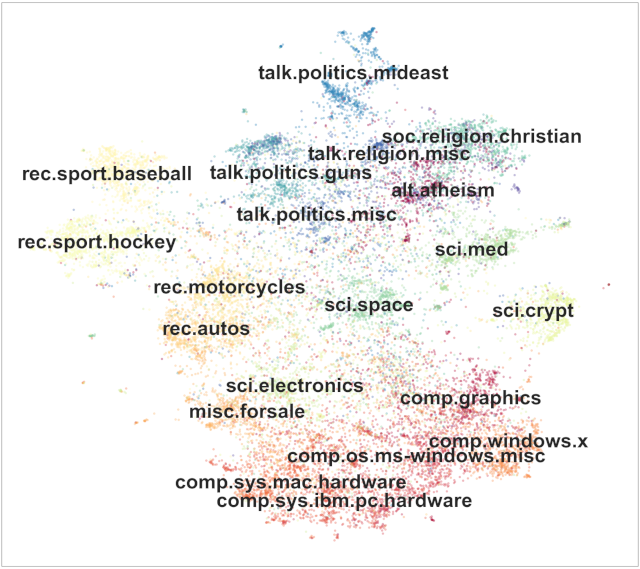
对于每个主题,您希望提取描述该主题的词语。

Sentence-Transformers可用于在一系列句子、段落或短文档中识别这些主题。要获取优秀的教程,请参阅 使用 BERT 进行主题建模 以及 BERTopic 和 Top2Vec 的代码仓库。
图片来源:Top2Vec:主题的分布式表示