MS MARCO
MS MARCO Passage Ranking 是一个大型数据集,用于训练信息检索模型。它包含大约 50 万个来自 Bing 搜索引擎的真实搜索查询,以及回答该查询的相关文本段落。
此页面展示了如何在 MS MARCO 数据集上训练交叉编码器模型,以便它可以用于搜索给定查询(关键词、短语或问题)的文本段落。
如果您对如何使用这些模型感兴趣,请参阅 应用 - 检索 & 重排序。
有预训练模型可用,您可以直接使用它们,而无需训练自己的模型。有关更多信息,请参阅 预训练交叉编码器。
交叉编码器
交叉编码器 接受两个输入,查询和可能的相关段落,并返回一个介于 0 和 1 之间的分数,表示该段落与给定查询的相关性。
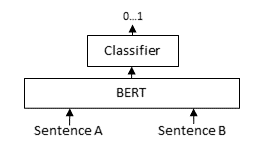
交叉编码器通常用于重排序:给定一个查询的可能相关段落列表,例如从 BM25 / Elasticsearch 检索的列表,交叉编码器会重新排序此列表,以便最相关的段落位于结果列表的顶部。
要在 MS MARCO 数据集上训练交叉编码器,请参阅
train_cross-encoder_scratch.py 从头开始训练交叉编码器,使用来自 MS MARCO 数据集的提供数据。
交叉编码器知识蒸馏

train_cross-encoder_kd.py 使用知识蒸馏设置:Hostätter 等人 为 MS MARCO 数据集训练了一个由 3 个(大型)模型组成的集成模型,并预测了各种(查询,段落)对的分数(50% 正例,50% 负例)。在此示例中,我们使用知识蒸馏与小型且快速的模型,并从教师集成模型中学习 logits 分数。这产生了与大型模型相当的性能,同时速度快了 18 倍。