无监督学习
此页面包含一系列无监督学习方法,用于学习句子嵌入。这些方法的共同点是它们不需要标注的训练数据。相反,它们可以仅从文本本身学习语义上有意义的句子嵌入。
注意
无监督学习方法仍然是一个活跃的研究领域,在许多情况下,与使用我们的训练数据集合中提供的训练对的模型相比,这些模型的性能相当差。更好的方法是领域自适应,它将目标领域的无监督学习与现有的标注数据相结合。这应该在您的特定语料库上提供最佳性能。
TSDAE
在我们的工作TSDAE(基于 Transformer 的去噪自动编码器)中,我们提出了一种基于去噪自动编码器的无监督句子嵌入学习方法
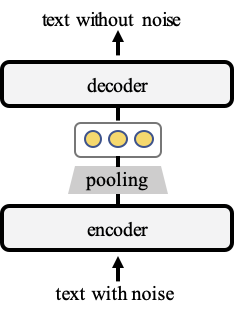
我们向输入文本添加噪声,在我们的例子中,我们删除了文本中约 60% 的单词。编码器将此输入映射到固定大小的句子嵌入。然后,解码器尝试重新创建没有噪声的原始文本。之后,我们将编码器用作句子嵌入方法。
有关更多信息和训练示例,请参阅TSDAE。
SimCSE
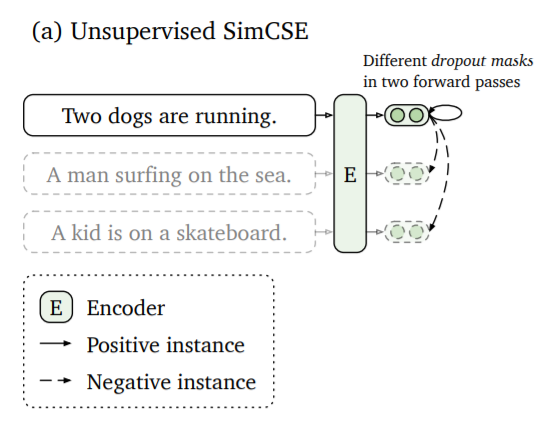
Gao 等人在SimCSE:句子嵌入的简单对比学习中提出了一种方法,该方法将相同的句子两次传递给句子嵌入编码器。由于 dropout,它将在向量空间中略有不同的位置进行编码。
这两个嵌入之间的距离将最小化,而与同一批次中其他句子的其他嵌入的距离将最大化。
有关更多信息和训练示例,请参阅SimCSE。
CT
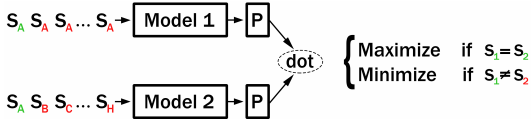
Carlsson 等人在具有对比张力 (CT) 的语义再调整中提出了一种使用两个模型的无监督方法:如果将相同的句子传递给模型 1 和模型 2,则相应的句子嵌入应获得较大的点积分数。如果传递不同的句子,则句子嵌入应获得较低的分数。
有关更多信息和训练示例,请参阅CT。
CT(In-Batch Negative Sampling)
Carlsson 等人的 CT 方法向两个模型提供句子对。可以通过使用 in-batch negative sampling 来改进这一点:模型 1 和模型 2 都编码相同的句子集。我们最大化匹配索引的分数(即 Model1(S_i) 和 Model2(S_i)),同时我们最小化不同索引的分数(即 Model1(S_i) 和 Model2(S_j),其中 i != j)。
有关更多信息和训练示例,请参阅CT_In-Batch_Negatives。
Masked Language Model (MLM)
BERT 表明,Masked Language Model (MLM) 是一种强大的预训练方法。建议首先在您领域的大型数据集上运行 MLM,然后再进行微调。有关更多信息和训练示例,请参阅MLM。
GenQ
在我们的论文BEIR:信息检索模型零样本评估的异构基准中,我们提出了一种通过为给定段落生成查询来学习语义搜索方法的方法。此方法在GPL:用于密集检索的无监督领域自适应的生成式伪标签中得到了改进。
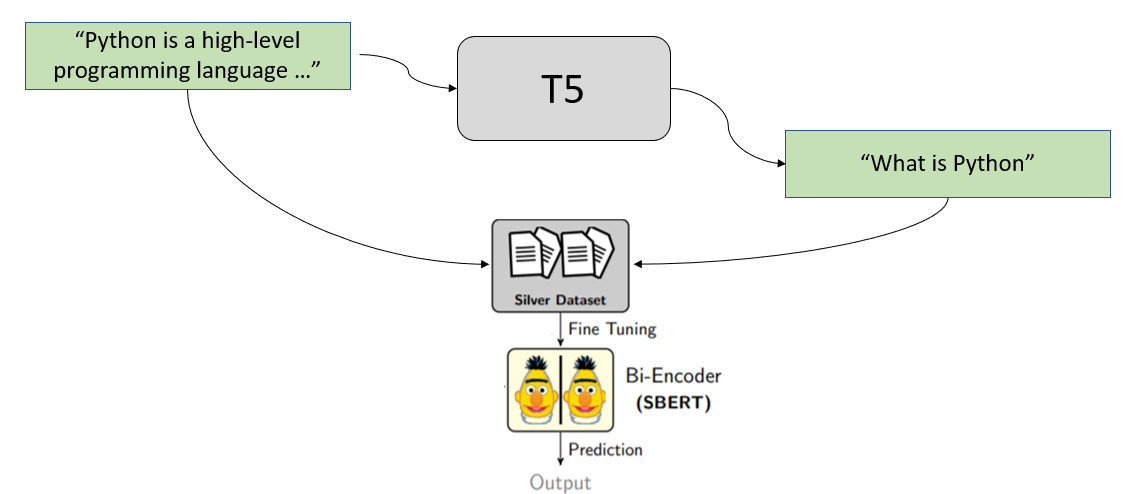
我们将我们集合中的所有段落通过训练好的 T5 模型,该模型生成来自用户的潜在查询。然后,我们使用这些(查询,段落)对来训练 SentenceTransformer 模型。
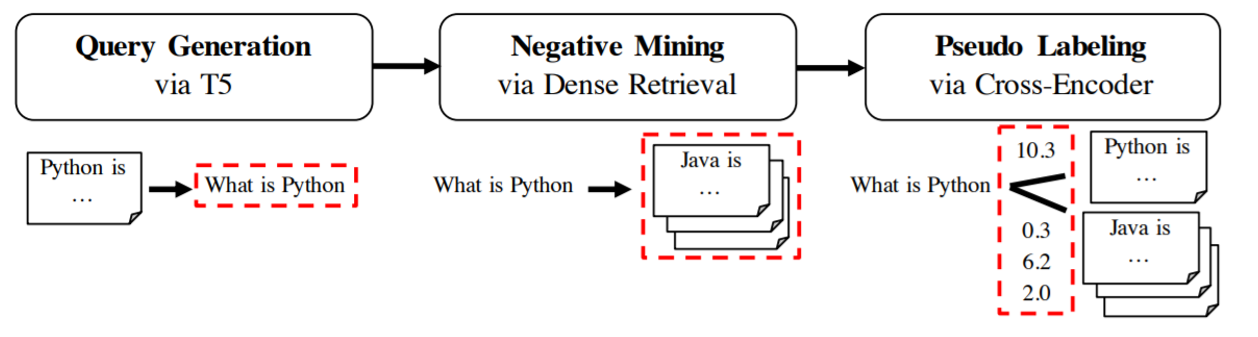
GPL
在GPL:用于密集检索的无监督领域自适应的生成式伪标签中,我们展示了 GenQ 的改进版本,它将生成与负样本挖掘和使用 Cross-Encoder 的伪标签相结合。它显着提高了结果。有关更多信息,请参阅领域自适应。
性能比较
在我们的论文TSDAE中,我们比较了句子嵌入任务的方法,在GPL中,我们比较了它们用于语义搜索任务的方法(给定查询,查找相关段落)。虽然无监督方法在句子嵌入任务中实现了可接受的性能,但它们在语义搜索任务中的表现很差。