TSDAE
本节展示了一个示例,说明我们如何使用纯句子作为训练数据来训练一个无监督的 TSDAE(基于 Transformer 的去噪自编码器)模型。
背景
在训练过程中,TSDAE 将受损的句子编码成固定大小的向量,并要求解码器从这些句子嵌入中重建原始句子。为了获得良好的重建质量,语义必须在编码器的句子嵌入中被很好地捕获。之后,在推理时,我们只使用编码器来创建句子嵌入。其架构如下图所示:
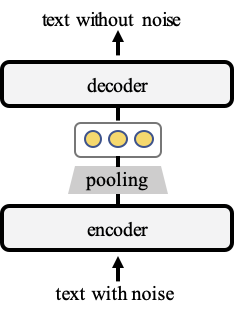
使用 TSDAE 进行无监督训练
使用 TSDAE 进行训练很简单。你只需要一组句子。
from sentence_transformers import SentenceTransformer, LoggingHandler
from sentence_transformers import models, util, datasets, evaluation, losses
from torch.utils.data import DataLoader
# Define your sentence transformer model using CLS pooling
model_name = "bert-base-uncased"
word_embedding_model = models.Transformer(model_name)
pooling_model = models.Pooling(word_embedding_model.get_word_embedding_dimension(), "cls")
model = SentenceTransformer(modules=[word_embedding_model, pooling_model])
# Define a list with sentences (1k - 100k sentences)
train_sentences = [
"Your set of sentences",
"Model will automatically add the noise",
"And re-construct it",
"You should provide at least 1k sentences",
]
# Create the special denoising dataset that adds noise on-the-fly
train_dataset = datasets.DenoisingAutoEncoderDataset(train_sentences)
# DataLoader to batch your data
train_dataloader = DataLoader(train_dataset, batch_size=8, shuffle=True)
# Use the denoising auto-encoder loss
train_loss = losses.DenoisingAutoEncoderLoss(
model, decoder_name_or_path=model_name, tie_encoder_decoder=True
)
# Call the fit method
model.fit(
train_objectives=[(train_dataloader, train_loss)],
epochs=1,
weight_decay=0,
scheduler="constantlr",
optimizer_params={"lr": 3e-5},
show_progress_bar=True,
)
model.save("output/tsdae-model")
从句子文件创建 TSDAE
train_tsdae_from_file.py 从提供的文本文件中加载句子。该文本文件应为每行一个句子。
TSDAE 将使用这些句子进行训练。检查点每 500 步保存到输出文件夹中。
在 AskUbuntu 数据集上使用 TSDAE
AskUbuntu 数据集是为 AskUbuntu 论坛手动标注的数据集。对于 400 个问题,专家为每个问题标注了另外 20 个问题是否相关。这些问题被分为训练集和开发集。
train_askubuntu_tsdae.py - 展示了一个示例,说明如何仅使用句子而无需任何标签在 AskUbuntu 上训练模型。作为句子,我们使用未在开发/测试集中使用的标题。
| 模型 | 测试集上的 MAP 分数 |
|---|---|
| TSDAE (bert-base-uncased) | 59.4 |
| 预训练的 SentenceTransformer 模型 | |
| nli-bert-base | 50.7 |
| paraphrase-distilroberta-base-v1 | 54.8 |
| stsb-roberta-large | 54.6 |
TSDAE 作为预训练任务
正如我们在TSDAE 论文中展示的,TSDAE 也是一种强大的预训练方法,其性能优于经典的掩码语言模型(MLM)预训练任务。
你首先使用 TSDAE 损失来训练你的模型。在训练了一定数量的步骤后/模型收敛后,你可以像其他任何 SentenceTransformer 模型一样进一步微调你的预训练模型。
引用
如果您使用该代码进行增强型 SBERT,欢迎引用我们的出版物 TSDAE: Using Transformer-based Sequential Denoising Auto-Encoderfor Unsupervised Sentence Embedding Learning
@article{wang-2021-TSDAE,
title = "TSDAE: Using Transformer-based Sequential Denoising Auto-Encoderfor Unsupervised Sentence Embedding Learning",
author = "Wang, Kexin and Reimers, Nils and Gurevych, Iryna",
journal= "arXiv preprint arXiv:2104.06979",
month = "4",
year = "2021",
url = "https://arxiv.org/abs/2104.06979",
}